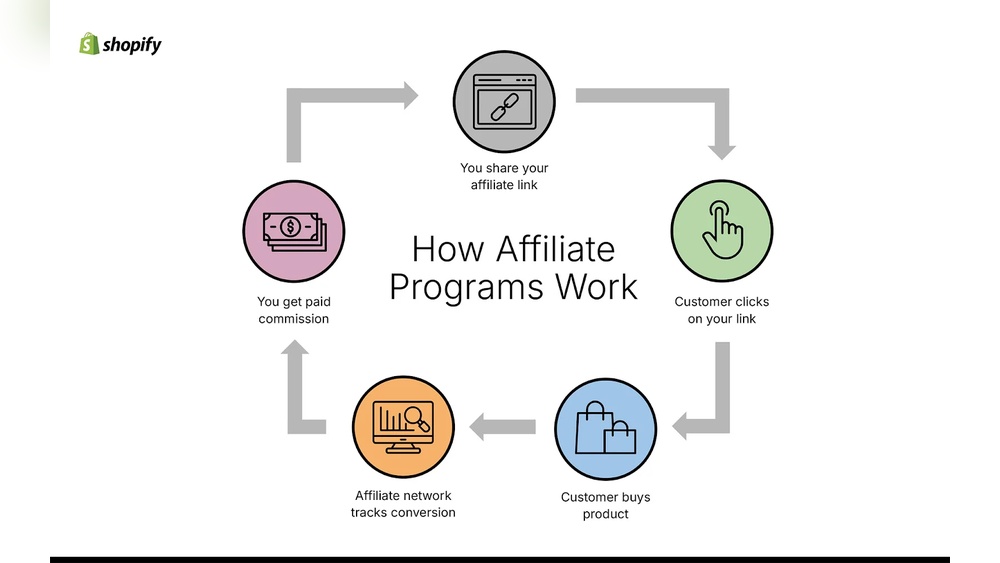
Sammanfattning:
- LLM-optimering förbättrar prestanda och minskar kostnader med teknik som model routing, prompt caching och kvantisering. Genom att kombinera dessa metoder kan företag sänka sina API-kostnader med upp till 80 procent. Effektiv GPU-hantering och kontinuerlig mätning är avgörande för bästa resultat i produktion.
LLM optimization är processen att förbättra prestanda, kostnadseffektivitet och precision i stora språkmodeller genom tekniker som model routing, kvantisering och GPU-minneshantering. Inom branschen används ofta termen “LLM-optimering” parallellt med det engelska uttrycket. För teknikansvariga är detta inte en teoretisk fråga. Företag kan sänka månatliga API-kostnader med upp till 80 procent genom rätt kombination av prompt caching, model routing och utdataoptimering. Det innebär att en månadskostnad på 100 000 kronor kan pressas ned till 20 000 kronor utan att kvaliteten försämras märkbart. Verktygen finns redan. Frågan är om din organisation använder dem.
Vilka är de mest effektiva teknikerna för LLM optimization?
De fyra teknikerna som ger störst effekt i produktion är model routing, prompt caching, kvantisering och finjustering med QLoRA. Varje metod löser ett specifikt problem och de kompletterar varandra.
Model routing dirigerar enkla frågor till mindre, billigare modeller och reserverar de stora modellerna för komplexa uppgifter. Model routing sänker kostnader med 60–80 procent utan nämnvärd kvalitetsförlust. Det är den enskilt snabbaste åtgärden för de flesta verksamheter.

Prompt caching sparar resultaten från upprepade indata-tokens och återanvänder dem vid liknande förfrågningar. Tekniken minskar beräkningskostnaden kraftigt när samma systemprompter används om och om igen, vilket är vanligt i kundtjänstapplikationer och interna assistenter.
Kvantisering komprimerar modellvikterna från 16-bitars till lägre precision, exempelvis 4-bitars eller 3-bitars representation. Det minskar minneskravet och ökar hastigheten. QLoRA kombinerar kvantisering med finjustering och gör det möjligt att träna om en modell på konsumenthårdvara.
Retrieval-Augmented Generation (RAG) hämtar relevant information från externa databaser i stället för att baka in all kunskap i modellen. RAG bör övervägas före finjustering eftersom finjustering med QLoRA är mest effektivt när beteendet hos modellen ska ändras, inte bara kunskapsbasen.
| Teknik | Förväntad kostnadsbesparing | Prestanda | Komplexitet |
|---|---|---|---|
| Model routing | 60–80 % | Hög | Låg |
| Prompt caching | 20–40 % | Hög | Låg |
| Kvantisering (QLoRA) | 30–50 % | Medel | Medel |
| RAG | 10–30 % | Hög | Medel |
| Finjustering (full) | 0–20 % | Mycket hög | Hög |

Proffstips: Börja alltid med model routing och prompt caching. De kräver minst infrastrukturarbete och ger snabbast avkastning. Spara finjustering till de fall där modellens beteende verkligen behöver förändras.
Hur påverkar GPU-hantering och infrastruktur LLM-prestanda?
Infrastrukturval avgör hur mycket du faktiskt får ut av en modell i produktion. Vanliga flaskhalsar i LLM-prestanda är VRAM-kapacitet, minnesbandbredd och schemaläggning. VRAM-storleken är oftast den mest kritiska faktorn. En modell som inte ryms i GPU-minnet tvingas dela beräkningar mellan CPU och GPU, vilket ökar latensen dramatiskt.
PagedAttention löser ett av de mest kostsamma problemen i GPU-minneshantering: fragmentering. Traditionella system reserverar ett sammanhängande minnesblock per förfrågan, vilket leder till att stora delar av VRAM aldrig används. PagedAttention minskar GPU-minnesslöseri med 95 procent och höjer genomströmningen med 2–4 gånger vid samtidiga förfrågningar. Det är en av de mest konkreta prestandaförbättringarna tillgängliga i dag.
KV-cachekvantisering tar detta ett steg längre. TurboQuant-algoritmen komprimerar KV-cacheminnet från 16-bitars till 3-bitars representation och ökar hastigheten på attention-beräkningar med upp till åtta gånger. I tester med H100 GPU innebar det fem gånger mer datalagring i samma minnesutrymme. Det är en teknik som förändrar vad som är möjligt på befintlig hårdvara.
Infrastrukturval och schemaläggning är oftare större utmaningar än själva modellarkitekturen. Det är en insikt som många teknikansvariga missar när de fokuserar för mycket på modellval och för lite på hur modellen körs.
Proffstips: Mät VRAM-användning och minnesbandbredd kontinuerligt i produktion. Utan mätning vet du inte var flaskhalsen faktiskt sitter, och du riskerar att optimera fel del av systemet.
Spekulativ dekoding och prefill-optimering
Spekulativ dekoding är en teknik där en mindre modell genererar ett utkast som den stora modellen sedan verifierar. Det minskar antalet beräkningssteg. Spekulativ dekoding ger mest effekt om prefill-steget optimeras samtidigt. Annars är tidsvinsten marginell. Prefill och decode måste alltså hanteras parallellt för att tekniken ska ge verklig nytta.
Hur kombinerar du optimeringsmetoder för att sänka kostnaderna drastiskt?
Den mest effektiva strategin är att stapla flera tekniker i rätt ordning. Stegvis implementering ger kontroll och gör det lättare att mäta effekten av varje åtgärd.
- Prompt caching är startpunkten. Identifiera vilka systemprompter och kontextblock som upprepas i dina förfrågningar och aktivera caching för dem. Effekten syns direkt i API-kostnaderna.
- Model routing är nästa steg. Klassificera inkommande förfrågningar och dirigera enkla frågor till en mindre modell som GPT-4o mini eller Mistral 7B. Reservera de stora modellerna för komplexa uppgifter.
- Batchhantering samlar flera förfrågningar och bearbetar dem tillsammans. Batching av 32 förfrågningar minskar kostnaden per token med cirka 85 procent med liten påverkan på latens. Det är en av de mest underskattade teknikerna i produktion.
- Finjustering är det sista steget och används bara när de tidigare åtgärderna inte räcker. QLoRA gör det möjligt att finjustera på en enda GPU med begränsad VRAM.
“Att trimma utdata-tokens ger mer effekt än att trimma indata-tokens. En kortare svarsinstruktion i prompten kan halvera kostnaden per förfrågan utan att kvaliteten sjunker.”
Ett praktiskt exempel: ett företag med 100 000 kronor i månatliga LLM-kostnader kan nå 20 000 kronor per månad genom att kombinera prompt caching, model routing och batchhantering. Det kräver ingen ny hårdvara och inga nya modeller. Det kräver rätt konfiguration av befintliga verktyg.
Vanliga fallgropar inkluderar att hoppa direkt till finjustering utan att testa enklare metoder, att inte mäta baslinjen innan optimering påbörjas, och att optimera för latens när kostnaden är det verkliga problemet. Välj ett primärt mål och mät mot det.
Vad innebär framtidens LLM-optimering för mindre företag?
Trenden pekar tydligt mot lokal körning och öppna modeller. Google DeepMind satsar på öppna och lokala modeller som ger bättre prestanda på billigare hårdvara. Det sänker tröskeln för AI-användning för små och medelstora företag som tidigare var beroende av dyra molntjänster.
TurboQuant och DiffusionGemma representerar en ny era med fokus på lokal körning och öppna modeller. DiffusionGemma är en ny arkitektur från Google DeepMind som genererar text parallellt i stället för sekventiellt. Det gör modellen snabbare och mer lämpad för lokal inferens på konsumenthårdvara.
Konsekvenserna för investeringsbeslut är konkreta:
- Lokal inferens ger full kontroll över data och uppfyller GDPR-krav utan att data lämnar organisationen.
- Öppna modeller som Llama 3, Mistral och Phi-3 kan köras på egna servrar och anpassas fritt.
- Molntjänster som OpenAI och Anthropic förblir relevanta för de mest komplexa uppgifterna, men behöver inte vara standardvalet.
- Kostnaden för lokal GPU-hårdvara sjunker kontinuerligt, vilket förbättrar kalkylen för on-premise-lösningar.
- Hybridarkitekturer, där enkla uppgifter körs lokalt och komplexa skickas till molnet, ger bäst balans mellan kostnad och prestanda.
För teknikansvariga innebär detta att AI och affärsutveckling nu är tillgängligt på en helt annan kostnadsnivå än för två år sedan. Beslutet om moln kontra on-premise handlar inte längre om prestanda utan om styrning, kostnad och datakontroll.
Viktiga insikter
LLM optimization kräver en kombination av model routing, prompt caching, batchhantering och GPU-minneshantering för att nå upp till 80 procents kostnadsbesparing i produktion.
| Punkt | Detaljer |
|---|---|
| Starta med model routing | Dirigera enkla förfrågningar till mindre modeller och sänk kostnaderna med 60–80 % direkt. |
| Aktivera prompt caching tidigt | Återanvändning av upprepade tokens minskar API-kostnaden utan kodändringar i affärslogiken. |
| Använd PagedAttention för GPU | Tekniken minskar minnesslöseri med 95 % och höjer genomströmningen med 2–4 gånger. |
| Batcha förfrågningar i produktion | 32 samlade förfrågningar sänker kostnaden per token med cirka 85 % med minimal latensökning. |
| Välj RAG före finjustering | RAG är snabbare och billigare att implementera; finjustering med QLoRA används bara när beteendet måste ändras. |
Vad jag lärt mig om LLM-optimering i praktiken
De flesta organisationer jag arbetat med gör samma misstag: de börjar med finjustering. Det låter avancerat och imponerande, men det är nästan alltid fel startpunkt. Finjustering är dyrt, tidskrävande och kräver märkta träningsdata som sällan finns tillgängliga i tillräcklig mängd. Resultaten är svåra att förutsäga och ännu svårare att underhålla.
Det som faktiskt fungerar är att börja med mätning. Utan en baslinje vet du inte vad du optimerar mot. Jag har sett teknikteam spendera månader på att finjustera en modell och sedan inse att prompt caching hade löst 70 procent av problemet på en vecka.
En annan sak som underskattas är utdataoptimering. De flesta fokuserar på att korta ned indata-prompterna, men det är utdata-tokens som kostar mest i de flesta API-prismodeller. En tydlig instruktion om svarsformat och längd kan halvera kostnaden per förfrågan. Det är en förändring som tar en timme att implementera.
Infrastrukturfrågorna är genuint svåra. VRAM-fragmentering, schemaläggning och minnesbandbredd är problem som kräver djup teknisk kompetens. Här är det värt att investera i rätt verktyg, som vLLM för PagedAttention-stöd, i stället för att försöka lösa det manuellt. Verktyget existerar. Använd det.
Min starkaste rekommendation: behandla LLM-optimering som ett kontinuerligt arbete, inte ett engångsprojekt. Modeller uppdateras, användningsmönster förändras och prismodeller justeras. Det team som mäter och justerar löpande vinner mot det team som optimerade en gång och sedan gick vidare.
— Peter
Hivecreatives hjälper dig att omsätta teknikstrategier i praktiken
Att förstå LLM-optimering är en sak. Att integrera det i en digital strategi som faktiskt driver tillväxt är en annan. Hivecreatives arbetar med företag som vill koppla ihop teknikval med affärsmål, från webbarkitektur till innehållsstrategi.
Om du vill att din digitala närvaro ska hålla jämna steg med de tekniska möjligheterna är en välbyggd webbplattform grunden. Hivecreatives erbjuder anpassad webbdesign och teknikstrategi som är byggd för att stödja just den typen av tillväxt. Ta kontakt för en kostnadsfri konsultation och se vad som är möjligt för din verksamhet.
Vanliga frågor
Vad är LLM optimization?
LLM optimization är processen att förbättra prestanda och kostnadseffektivitet hos stora språkmodeller genom tekniker som model routing, kvantisering, prompt caching och GPU-minneshantering. Målet är att sänka driftskostnader och öka genomströmning utan att kvaliteten försämras.
Hur mycket kan LLM-kostnader minskas med optimering?
Företag kan sänka månatliga LLM API-kostnader med upp till 80 procent genom att kombinera prompt caching, model routing och batchhantering. En månadskostnad på 100 000 kronor kan pressas ned till 20 000 kronor med rätt konfiguration.
Vad är skillnaden mellan RAG och finjustering?
RAG hämtar information från externa databaser vid varje förfrågan och kräver ingen träning av modellen. Finjustering med QLoRA tränar om modellen på ny data och används när modellens beteende behöver förändras, inte bara dess kunskapsbas.
Vad är PagedAttention och varför spelar det roll?
PagedAttention är en teknik för GPU-minneshantering som eliminerar fragmentering i KV-cachen. Den minskar minnesslöseri med 95 procent och höjer genomströmningen med 2–4 gånger, vilket gör den till en av de mest effektiva prestandaförbättringarna för LLM-servering i produktion.
Ska mitt företag köra LLM lokalt eller i molnet?
Lokal körning ger full datakontroll och uppfyller GDPR-krav, men kräver investering i GPU-hårdvara. Molntjänster är enklare att komma igång med men dyrare vid hög volym. En hybridarkitektur, där enkla uppgifter körs lokalt och komplexa skickas till molnet, ger ofta bäst balans.